CoreDNS大屏看板、监控、和企业微信告警通知
在前面三篇文章中分别介绍了DNS域名解析原理,安装CoreDNS,以及如何基于CoreDNS实现GSLB,这篇文章主要是运维相关,将介绍如何监控CoreDNS的运行状态并进行企业微信告警通知。
本文会按照如下步骤进行展开描述:
- 快速搭建Prometheus+Grafana监控环境
- 采集 CoreDNS 监控指标
- Grafana 可视化看板展示
- Grafana 企业微信告警
快速搭建Prometheus+Grafana监控环境
快速搭建 Prometheus+Grafana 监控环境可以基于 Docker Compose 的方式进行搭建,具体的 docker-compose.yml 配置文件如下:
镜像使用 藏云阁镜像仓库,在国内可以高速下载镜像
services:
prometheus:
image: registry.cncfstack.com/docker.io/prom/prometheus:v3.9.1
container_name: prometheus
restart: always
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- /data/prometheus:/prometheus:Z
grafana:
image: registry.cncfstack.com/docker.io/grafana/grafana:12.4.0-20836657505
container_name: grafana
restart: always
ports:
- "3000:3000"
volumes:
- /data/grafana:/var/lib/grafana:Z
需要注意 prometheus 和 grafana 的数据目录需要提供权限,否则会由于缺少权限无法正常启动
chmod 755 /data/prometheus -R
chmod 755 /data/grafana -R
添加完后,启动容器
docker-compose up -d
这样就搭建好了 Prometheus+Grafana 监控环境,接下来就可以进行采集 CoreDNS 监控指标了。
采集 CoreDNS 监控指标
采集 CoreDNS 指标首先需要在 Corefile 配置文件中启用 prometheus 插件。
. {
log
errors
health :5380
prometheus :9153
.....
}
在添加完配置并重启CoreDNS的服务后,可以通过 curl 访问 9153 端口的 /metrics 接口来获取监控指标
curl http://127.0.0.1:9153/metrics
然后就可以通过 Prometheus 来采集这些指标了。
在前面的 docker-compose.yml 中,挂载了配置 prometheus.yml 配置文件,在该文件中添加如下配置:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'coredns'
static_configs:
- targets:
- '1.2.3.4:9153'
- '5.6.7.8:9153'
scrape_interval: 30s
这里的 1.2.3.4 和 5.6.7.8 是 CoreDNS 的 IP地址,可以根据实际情况进行修改。
Grafana 可视化看板展示
CoreDNS 的 Grafana 看板可以直接通过 grafana/dashboards 查询后通过ID导入模板,或者使用类似 coredns-mixin 的仓库基于 jsonnet 渲染模板导入。
不过我这边主要关注的内容不同,所以我自己进行了定义 CoreDNS 看板,并提供对应看板的 PromSQL 参考。
总请求量和每天的请求量
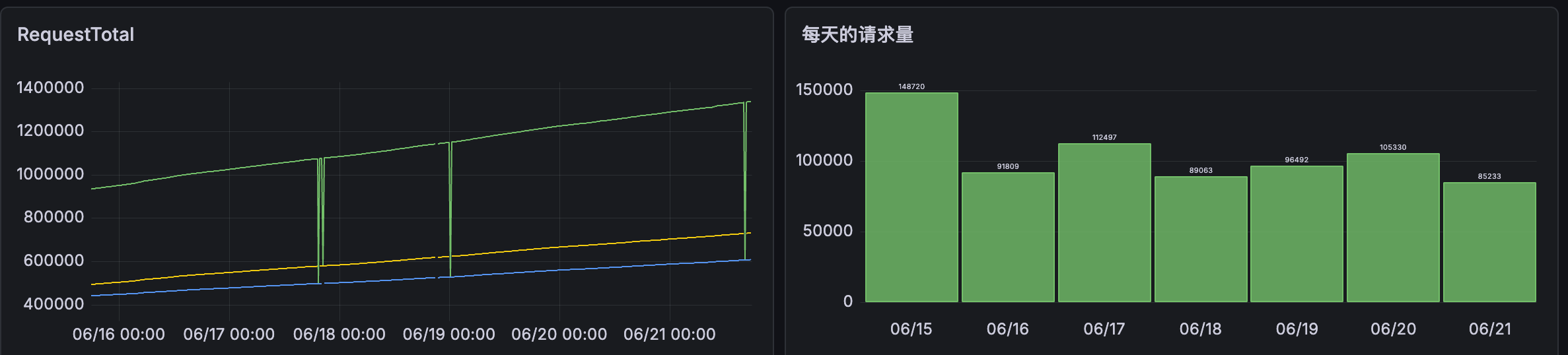
总请求量 的作用是统计所有CoreDNS实例的所有总请求量,但是如果CoreDNS重启这个数据会被重置,所以这个值只是一个参考值。
sum(coredns_dns_do_requests_total)
sum by (instance) (coredns_dns_do_requests_total)
每天的请求量 是统计每天的请求量,这个值是有价值的请求量数据。这个也是前面阿里云DNS每日限额的对象。
sum(increase(coredns_dns_requests_total[$__interval]))
通过这几天的监控数据,可以看到每天的请求量基本在 10万次/天 左右,距离阿里云统计的 239万次/天 是差很多的。
推测可能是因为阿里云DNS统计了用户直接的请求,实际权威域名解析的请求量没有那么大,而用户的直接请求(如配置223.5.5.5)是没法收费的。这样的话,阿里云DNS收费策略就有问题了,收费(统计)的对象应该是权威解析提供的云服务,而普通用户的递归解析本来就是免费,为啥要算到企业头上?
请求频率QPS和响应延迟
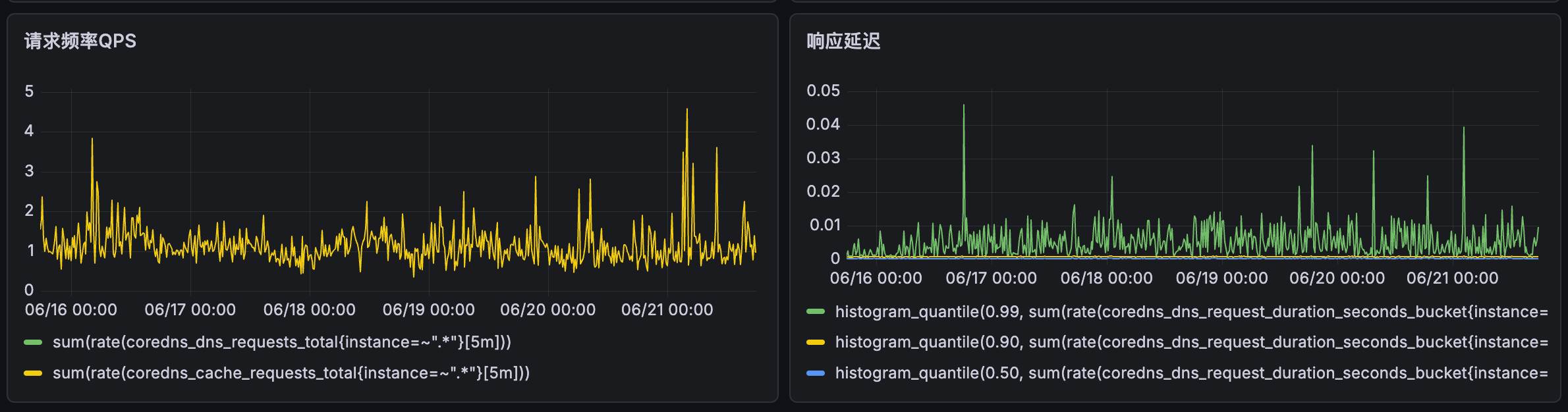
请求频率QPS 是统计每秒钟的请求量,这个值是实时变化的,所以可以用来监控 CoreDNS 的性能和负载情况。
实际数据中可以看到实际每秒的请求数量大概 1.5个/秒,估算每天 3600*24*1.5=129600, 这个量和实际统计的数据差不多。
sum(rate(coredns_dns_requests_total{instance=~"$instance"}[5m]))
sum(rate(coredns_cache_requests_total{instance=~"$instance"}[5m]))
响应延迟 是DNS解析的延迟,分为99%、90%、50%三种情况,整体的延迟毫秒级别,个别峰值毛刺对实际用户解析没有明显影响。
histogram_quantile(0.99, sum(rate(coredns_dns_request_duration_seconds_bucket{instance=~"$instance", zone="."}[5m])) by (le))
histogram_quantile(0.90, sum(rate(coredns_dns_request_duration_seconds_bucket{instance=~"$instance", zone="."}[5m])) by (le
histogram_quantile(0.50, sum(rate(coredns_dns_request_duration_seconds_bucket{instance=~"$instance", zone="."}[5m])) by (le))
区域、服务器和类型占比
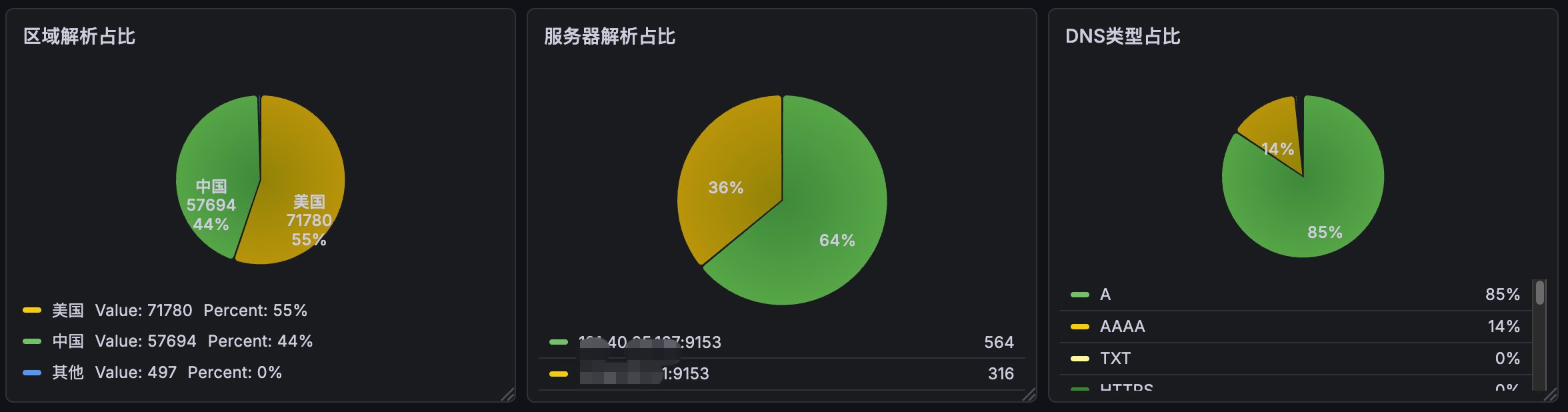
区域解析占比 是统计不同的区域解析占比,由于配置文件中主要区分了 china、usa、global 三种区域,所以这里统计了这三种区域的解析占比。
sum(increase(coredns_dns_requests_total{view="china"}[24h]))
sum(increase(coredns_dns_requests_total{view="usa"}[24h]))
(
# 获取所有请求(所有视图的总和)
sum(increase(coredns_dns_requests_total[24h]))
-
# 减去中国区
sum(increase(coredns_dns_requests_total{view="china"}[24h]))
-
# 减去美国区
sum(increase(coredns_dns_requests_total{view="usa"}[24h]))
)
服务器解析占比 是统计不同的 DNS 服务器解析占比。由于DNS服务器在配置时分为主从两类,通过数据可以看出来主从的流量比为 2:1
sum(rate(coredns_dns_requests_total[5m])) by (instance)
DNS类型占比 是统计不同的DNS类型占比,这里主要统计了 A、AAAA、CNAME、MX、NS、SOA、SRV、TXT 这几种类型。
sum(rate(coredns_dns_requests_total{instance=~"$instance"}[24h])) by (type)
Grafana 企业微信告警
前面是通过 Grafana 来展示监控数据,但是我们还需要在监控数据出现异常时进行告警和通知。
Grafana在 10.x 版本后的告警功能功能相对完善,直接使用 Grafana 告警功能就不需要在引入 AlertManager 了。
配置企业微信告警渠道
在 Grafana 中告警渠道称为联络点,我们习惯上称为告警通知渠道。Grafana 默认使用 Email 渠道进行告警通知,同时也支持钉钉、企业微信等渠道,这里我们使用企业微信进行告警。
1. 在企业微信中创建机器人并获取 Webhook 地址
在企业微信群中添加一个告警机器人可以使群中相关人员快速获取告警事件,通过一下步骤可以获取 Webhook 地址。
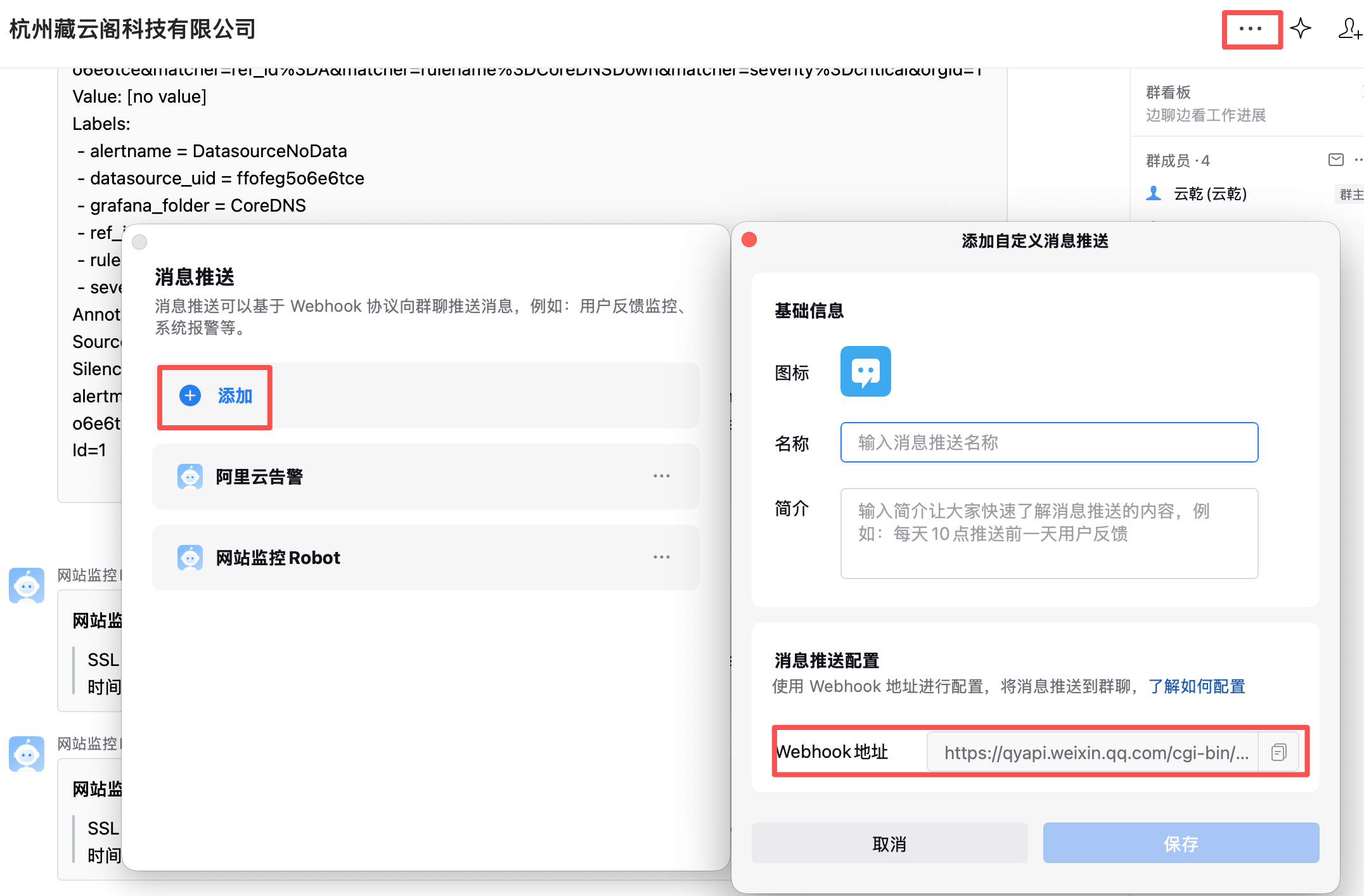
- 进入群设置:打开并登录企业微信,进入需要接收告警的群聊,点击右上角的“…”图标(手机端)或“管理聊天信息”(电脑端)。
- 添加机器人:在群设置页面找到并点击“消息推送”(或“群机器人”),然后点击“添加”。
- 新建机器人:选择“新创建一个机器人”(或“添加自定义消息推送”),为其设置一个有意义的名称(如“运维告警中心”)和头像,点击添加。
- 获取 Webhook 地址:创建成功后,系统会生成一个专属的 Webhook 地址。请立即复制并妥善保存该地址13。
Webhook 地址示例:
https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=650xxxxc-xxxx-4bef-xxxx-2bcf0xxxx2d
⚠️ 安全提醒:Webhook 地址包含了机器人的唯一密钥(Key),相当于机器人的密码。请务必像保管密码一样妥善保管,切勿泄露。如果不慎泄露,可以回到机器人设置中重置以获取新地址。
2. 在Grafana中配置企业微信告警渠道(联络点)
在 Grafana 的 警报->联络点 中添加选择 wecom 企业微信告警渠道,并配置 Webhook 地址。
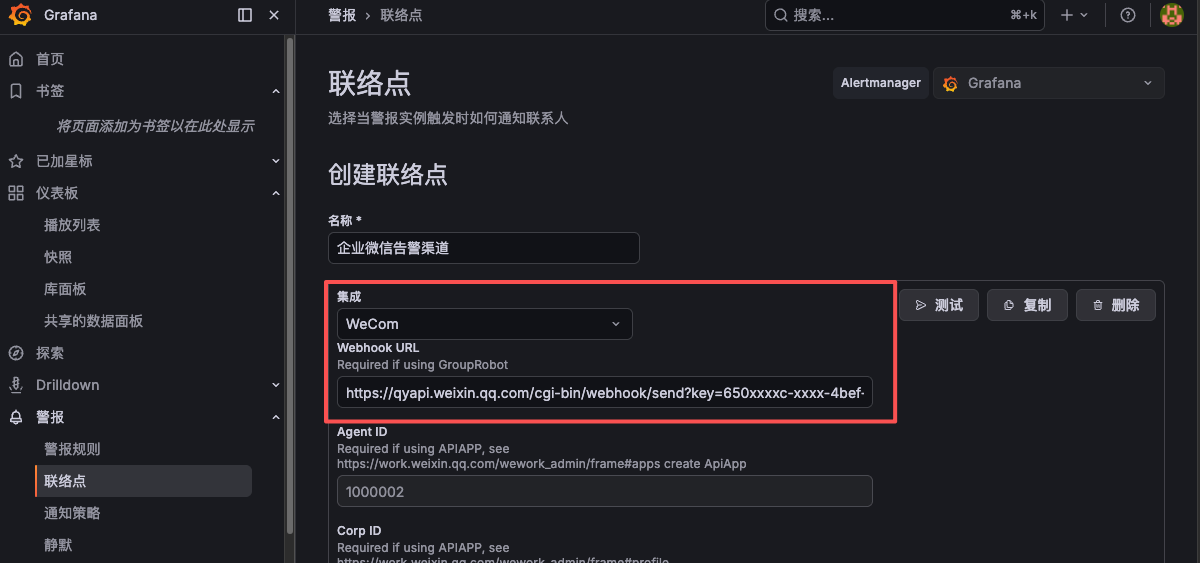
添加完告警渠道后,在后续的告警规则中可以选择该告警渠道进行告警通知。
告警规则配置
用 Grafana 监控 CoreDNS 并配置告警规则,核心思路是覆盖它的可用性、性能、错误率这几个关键方面。
可以参考 coredns-mixin 的仓库基于 jsonnet 渲染告警模板, 这个主要是面向 Kuberentes 的,所以需要将配置中的 kube-dns 修改 coredns。
我选择其中三个核心的 CoreDNS 告警规则 CoreDNSDown、CoreDNSLatencyHigh 和 CoreDNSErrorsHigh 进行配置。
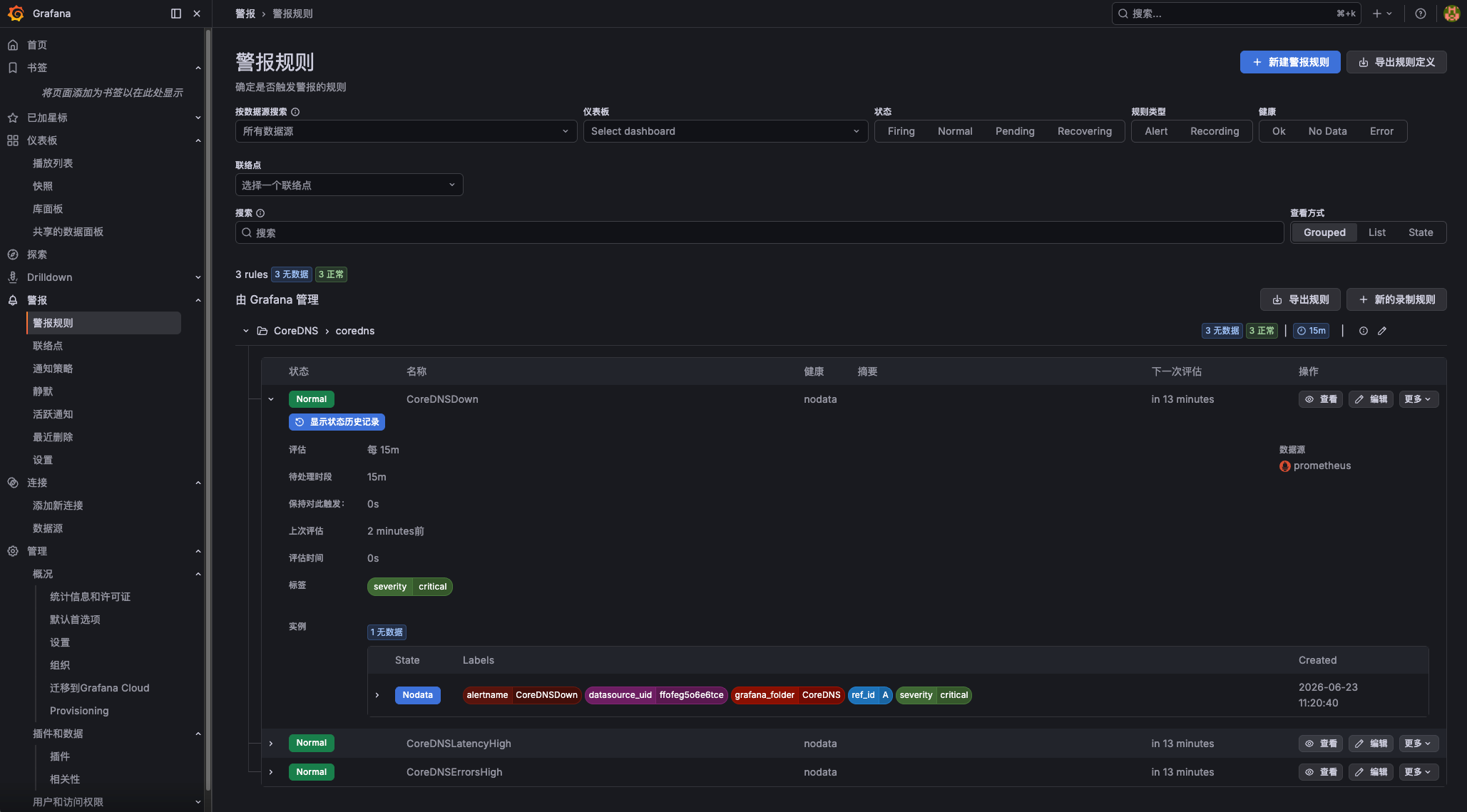
- 规则一:CoreDNSDown
CoreDNSDown 规则是检测 CoreDNS 实例不可用。当 Prometheus 无法从 CoreDNS 目标抓取到 up 指标(值为 1)时触发,意味着服务可能已挂掉或无法访问。
absent(up{job="coredns"} == 1)
- 规则二:CoreDNSLatencyHigh
CoreDNSLatencyHigh 规则检测 CoreDNS 实例响应延迟过高。
histogram_quantile(0.99, sum(rate(coredns_dns_request_duration_seconds_bucket{...}[5m])) by (le)) > 4
- 规则三:CoreDNSErrorsHigh
CoreDNSErrorsHigh 规则是检测 CoreDNS 实例错误率过高。
sum(rate(coredns_dns_responses_total{rcode="SERVFAIL"}[5m])) / sum(rate(coredns_dns_responses_total[5m])) > 0.01
要保证 CoreDNS 的稳定运行,“存活状态”、“请求延迟”、“错误率” 这三类告警是必不可少的“三件套”。在生产环境中,可以以社区方案(coredns-mixin)为标准模板进行配置,并根据自身业务负载调整具体的阈值 。
在 coredns-mixin 中还有其他告警规则,可以根据实际情况进行配置。
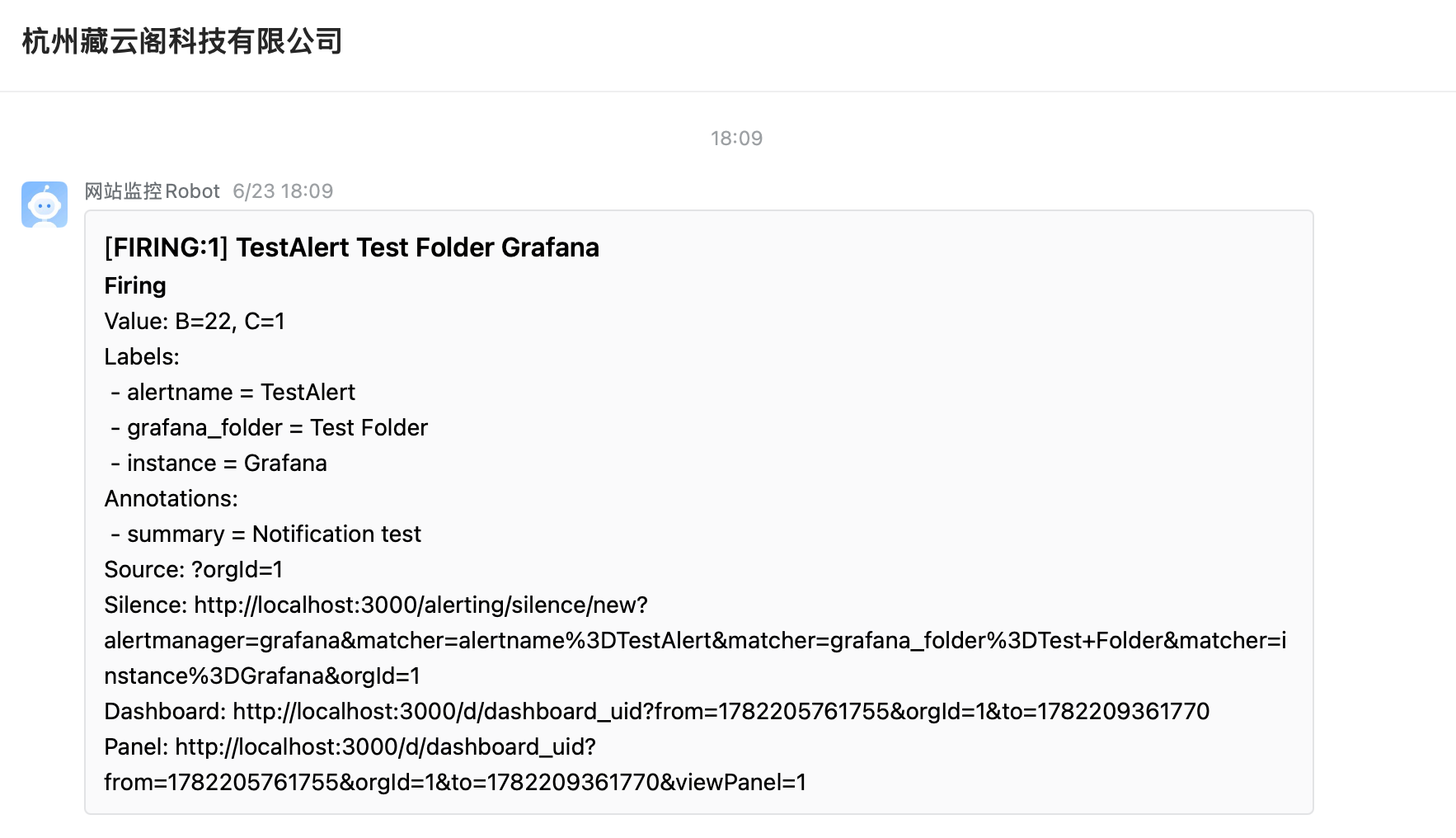
告警通知渠道验证
告警规则和告警渠道配置完成后,可以通过 Grafana 的告警测试功能来验证告警渠道是否正常。
总结
本文与前面几篇文章是一个系列,核心解决的问题就是:将 DNS 域名解析从云端迁移到自建的 CoreDNS 上。本文侧重于最后的运维管理部分,包括监控、告警、看板大屏等。
如果你对前面的文章有兴趣,可以参考